Twistrs — Domain name enumeration library in Rust
•if you want to skip all of the design and implementation fluff, simply head over to the Results section. The project can also be found here
Background
Most of my work comes from an information security background. I always had a growing fascination with Rust over the past couple of years (pre-1.0). This is my first attempt to really go full-circle with a very small project in hopes of contributing to the ecosystem. On a more personal note, it forces me to actually dig my teeth into the language till I finally feel productive with it.
Honourable Mentions
Normally this comes at the end of a blog post, however this seemingly small project took me months to get into a somewhat half-decent state, and it’s a huge thanks to the following folks.
- @erstejahre For really helping me discover and iron out some horrendous anti- patterns in initial implementations and for being a great person and a fantastic mentor.
- @sadisticsystems My first Rust tutor and a person who takes genuine pride and joy in sharing knowledge (irrespective of your background). Drastically helped get through first major hurdles in the project early on.
- @jonhoo While not someone I interacted with personally, Jon’s streams are of exceptionally quality for intermediate Rust that greatly demystified a lot of Rust concurrency models and internals.
Introduction
Domain typo-squatting1 is nothing new in the security world. There are many tools and services out there that already allow you to get a snapshot of your domain’s attack surface and even subscribe to certain notifications. One particular attack vector that interests me is email misdelivery2 and is something I would like to actively monitor for a number of domains.
Twistrs (twisters?) is my first attempt at releasing an open-source library in Rust (previously wrote a small tool called synner). The internals of the library are a direct port of the well-known dnstwist tool, that I personally loved and used a lot during many of my security engagements, with some minor modifications and changes.
The primary goals behind twistrs, similar to dnstwist, is to enable the following techniques.
- Permutation – Provide domain name permutation algorithms that are fast and simple to use. These are generally interesting techniques that are used for typo-squatting.
- Enrichment – Extend the library to allow enriching of domains by checking for resolvable domains, domains that are listening to misdirected mail and eventually other enrichment methods such as, but not limited to, HTTP banners, WHOIS lookup, GeoIP lookup and so on.
There are also some secondary requirements that really were the inspiration behind the port that are worth mentioning.
- Speed – being mostly network I/O bound, I want to make sure the library is noticeably faster to begin with, despite lacking experience in this area.
- Memory footprint – when hosting this, I want to drastically minimise cost of operations–particularly if we want to release a free web interface for users to use.
- Flexible interface – domain name permutation and enumeration must be disjoint, but still compliment each other. Additionally the library must not enforce any transport or concurrency implementations on the client.
- Go full circle – despite being a very small scope, I want to make sure to treat this like an actual library. Making sure there are tests, that it’s documented, maintained and that it’s published to crates.io.
Design
When brainstorming how I think the library would best suit potential users I wanted to make sure that users can pick and choose what they want to use while retaining control over how they want to transport information to-and-fro.
Want a REST API that generates and enriches a given domain? Go ahead. Want a CLI that only enriches a given domain with metadata as part of a larger tool? You can do that too.
With this in mind, the library broken down into two disjoint modules that can be used together to complement each other.
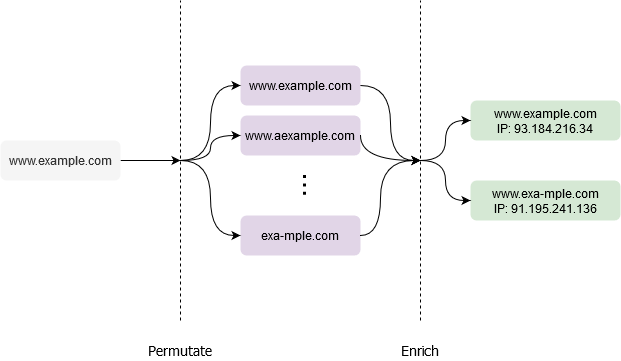
Or choose to skip permutation altogether and just enrich a specified domain with metadata.
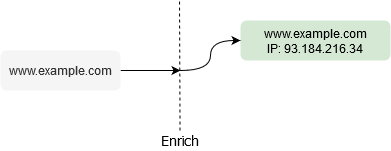
The transport layer is up to the client’s desired implementation. One trivial implementation is the twistrs-cli example that uses tokio mpsc to schedule a large number of host lookups and stream the results back.
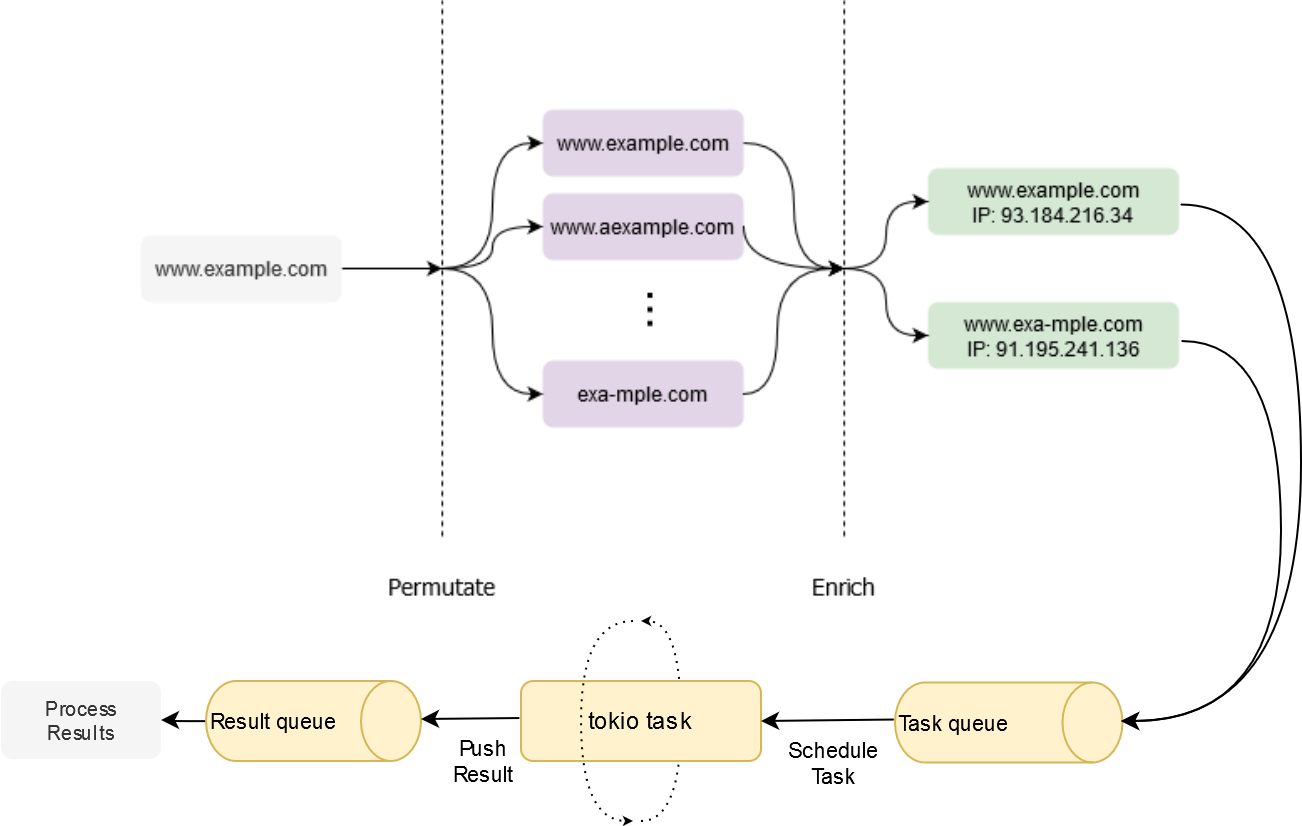
Note – the above diagram isn’t entirely correct, as there is only one queue, but it’s easier to visualise and wrap one’s head around.
At this point, I do not see this potentially changing all too much. In the future, it may make sense to provide some runtime out of the box that boils down the client implementation even further (would love to hear thoughts on this).
Implementation
Note – this section is somewhat long-winded. The aim here is to not just explain how I went about implementing the library, but really emphasise the (somewhat painful) journey that led to this point in hopes that it may help less experienced readers understand that brick walls are important to overall progress.
Implementation of the library started with the permutation engine first. The goals here are quite well defined and simple, so it made sense to start here.
- Map all the permutation methods that are available in dnstwist.py either equally, or slightly better (full list can be found here.
- Avoid complicating the interface by avoiding
async. This is in-memory string mutation, so the performance hit is beyond negligible.
Permutation
The sole purpose of the permutation module (permutate.rs) is to be able to, given a root domain, generate n similar variants of that domain. The initial implementation of the permutation generation was over-complicated and eventually rewritten.
All functionality is tied around a small data container, Domain, that stores some metadata that we use to generate our permutations.
The initial implementation had a single method named mutate that effectively acted as a single-entry for one or more permutation operations. Control-flow was determined by an unnecessary enum, PermutationMode.
The initial design philosophy here, was to try to make the interface easier to interact with by only having one entrypoint. The problem with this, as will soon be apparent, is that you are contrained to a lot of hidden behavior behind this one method.
Which meant that instead of doing something intuitive and simple like:
use Domain;
let homoglyph_permutations = newOne would need to resort to a less intuitive implementation with no additional benefit like so:
use ;
let homoglyph_permutations = new;
In the end, I opted for a much simpler implementation, removing the PermutationMode enum entirely, and simply making all the permutation methods public (there’s an all() method aggregates all permutation modes into a single iterator to achieve the original goal).
One other interesting change that I learned along the way, was to return iterators instead of vectors–allowing for some interesting chaining while being easier to operate with:
Original method signature
Revised Method Signature
The permutation methods themselves were quite fun to implement and helped play around with a lot of foundational operations in Rust. My particular favourite that I would like to highlight, is the bitsquatting implementation:
For details on how this technique works, I highly recommend recommend reading the referenced blog post3. There is not much left to mention for the permutation generator that is of particular interest. The domain enrichment is where some of the major challenges arise.
Enrichment
Domain enrichment is really the crux of the library in terms of its usefulness. While we can generate a large number of potential domains; sysadmins, security engineers, infosec officers and so on are particularly concerned with domains that:
- Are registered (i.e. resolve to an IP).
- Are actively hosting something (i.e. HTTP banner).
- Are actively receiving mail (i.e. MX check/SMTP Banner).
Any form of enrichment is generally going to be network I/O bound and assumedly very slow. This means that we need to make sure that (a) tasks are concurrent and (b) tasks are streamed as they are completed. This is relatively new area for me, so there was a lot of learning in this regard.
Before concerning myself with the performance aspect, the initial implementation followed similar roots to the permutation module. We have some DomainMetadata store that maintains interesting information we might want to pass on to the caller and an EnrichmentMode. Similarly, we had an overly complicated pub method named enrich that controlled flow depending on the EnrichmentMode.
type DomainStore = ;
The more astute reader might also notice the odd type alias, DomainStore. That was a very hacky way of trying to map an FQDN to some domain metadata in a way that was thread-safe. The idea here was to use Rayon’s into_par_iter() to handle parallelism and store all results in some “mutable domain store”.
let local_copy: = domains.iter.cloned.collect;
let resolved_domains = local_copy.into_par_iter.filter_map;
resolved_domains.into_par_iter.for_each;
The problem with this, apart from being unnecessarily complicated, is that the parallelism is now handled internally by the library, and the outer function (enrich) is blocking, which means that we take away control from the caller and are unable to stream results back. The result looks something like the following GIF:
This implementation clearly wasn’t going to cut it, so after some back and forth with @erstejahre, we came up with a couple of alternative approaches to the problem (even actix was on the table at this point).
Improvements
After some thought, I opted to boil things down to as simple as I could. The fewer language features, the better and the clearer the library will be.
The EnrichmentMode idea was scrapped entirely, and instead, the internal enrichment methods were boiled down into trivial async functions.
pub async
This is exceptionally trivial, easier to understand and gives power to the client to handle the concurrency flow themselves, however suits them best.
Side note–during initial implementation of the smtp enrichment check (i.e. can I send a dummy-email to this domain), I was making use of lettre, which is not async. I instead had to move to async_smtp which matches (more or less) the lettre interface, making moving to async literally a two-minute job!
The only major downside to this change, is that the client must now handle the task-scheduling mechanism themselves at all times, which albeit trivial for simpler examples, is not the most ideal. The good news is, that now results can be streamed back, to allow for faster and more responsive processing. Compare the following GIF to the one above.
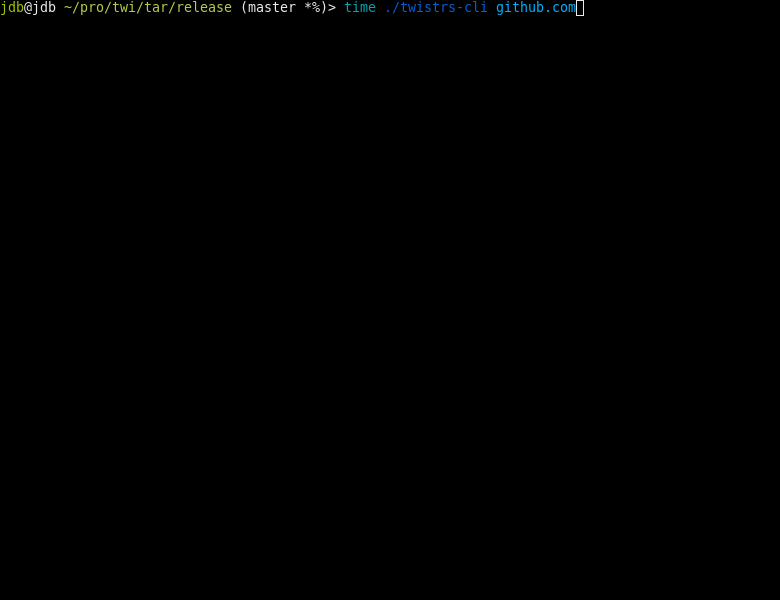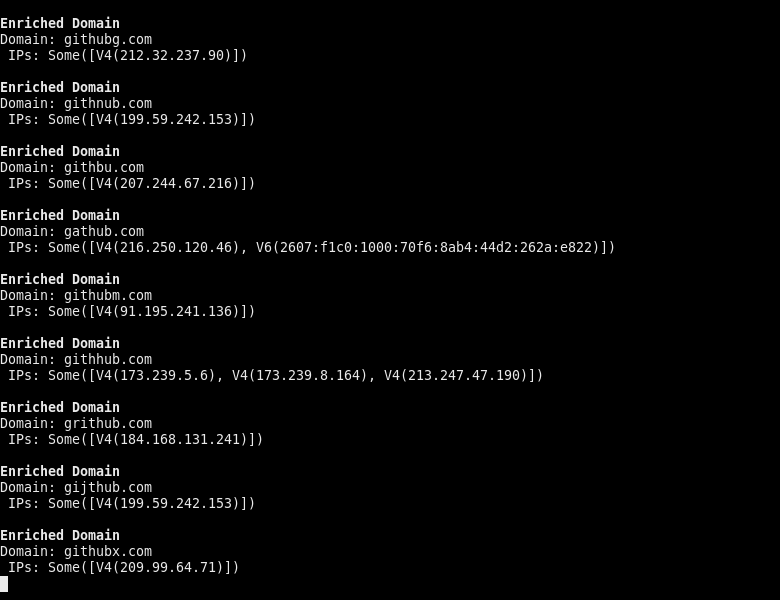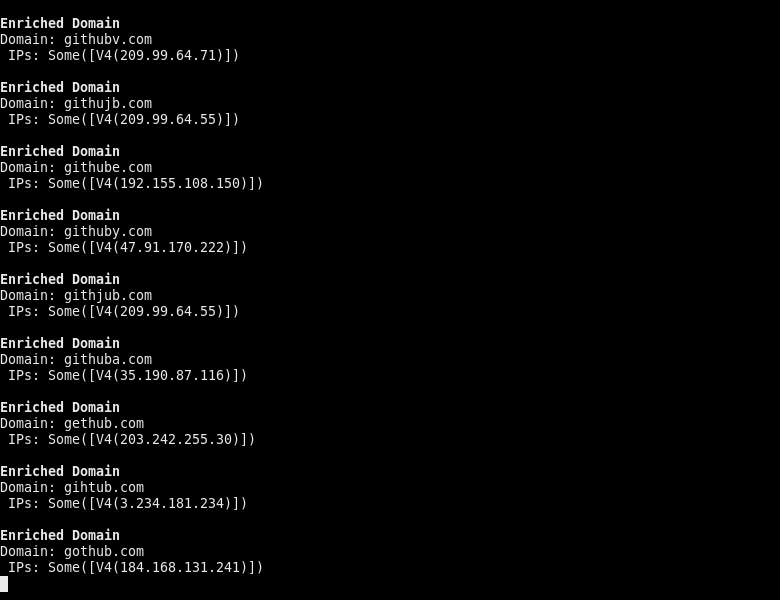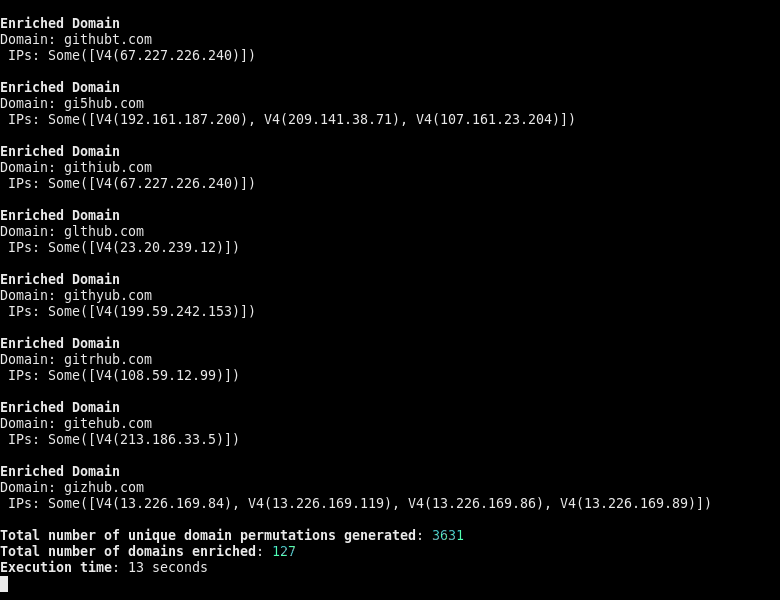
Another small downside here, is that since there is no shared-state between the async methods, they all return their own DomainMetadata for the same domain. This means that there needs to be some trivial fn join(metadata: Vec<DomainMetadata>) -> DomainMetadata that merges multiple DomainMetadata instances together into one.
Summary
After weeks of back-and-forth, we were able to come up with the building blocks of this micro-library. With some thoughtful rewrites, we were able to transform the library implementation from something complicated.
use HashMap;
use ;
use ;
use ;
let domain = new.unwrap;
match domain.permutate
To something that is somewhat more intuitive (yes, this is intentionally slow).
use DomainMetadata;
use Domain;
use block_on;
let domain = new.unwrap;
let domain_permutations = domain.all.unwrap;
for d in domain_permutations
Overall, I do not see the internals changing, however I do see an additional layer being added that handles the task execution out of the box. Really the aim here is to minimise the code required to get a simple implementation going.
Results
At this stage of the library, the primary objective was to match dnstwist in terms of permutation methods and at least:
- Cover two or more enrichment methods (Host lookup & SMTP check).
- Yield same number of hits or more.
- Execute at least in same amount of time or better.
Also keep in mind that these results are not really empirical, however they give a rough idea of the performance and results for now. Really the goal here is to detect very obvious red flags.
Raw data
The testing is quite trivial–compare dnstwist and twistrs-cli example against a list of domains that increase in char-length with each iteration.
The following is some of the raw data curated over initial tests. Each test was run 5 times and worst-case scenario was picked for both projects.
| domain | dnstwist_enriched | dnstwist_execution_time(s) | twistrs_enriched | twistrs_execution_time(s) |
|---|---|---|---|---|
| foo.com | 69 | 7 | 73 | 5 |
| yelp.com | 80 | 19 | 76 | 14 |
| chart.com | 101 | 25 | 108 | 14 |
| paypal.com | 139 | 26 | 144 | 17 |
| alibaba.com | 156 | 56 | 156 | 18 |
| linkedin.com | 178 | 52 | 158 | 18 |
| phishdeck.com | 1 | 51 | 2 | 11 |
| www.spotify.com | 106 | 19 | 147 | 18 |
| www.skynews.co.uk | 16 | 24 | 74 | 23 |
| sheets.google.com | 94 | 31 | 167 | 17 |
| www.cloudflare.com | 94 | 54 | 95 | 21 |
| purewaterplanet.com | 2 | 228 | 3 | 15 |
| microsoftonline.com | 118 | 144 | 122 | 21 |
| support.myshopify.com | 102 | 51 | 410 | 15 |
| blog.stackoverflow.com | 24 | 80 | 52 | 24 |
Note – for dnstwist, the tests were run with the
--registeredflag to ensure that only dns lookup is performed. Likewise, for twistrs onlydns_resolvable()was run.
Domains Enriched
The objective behind this graph is to make sure that twistrs is on-par with dnstwist in terms of the results it yields. For all occasions, bar one, twistrs yields the same number of registered domains or higher.
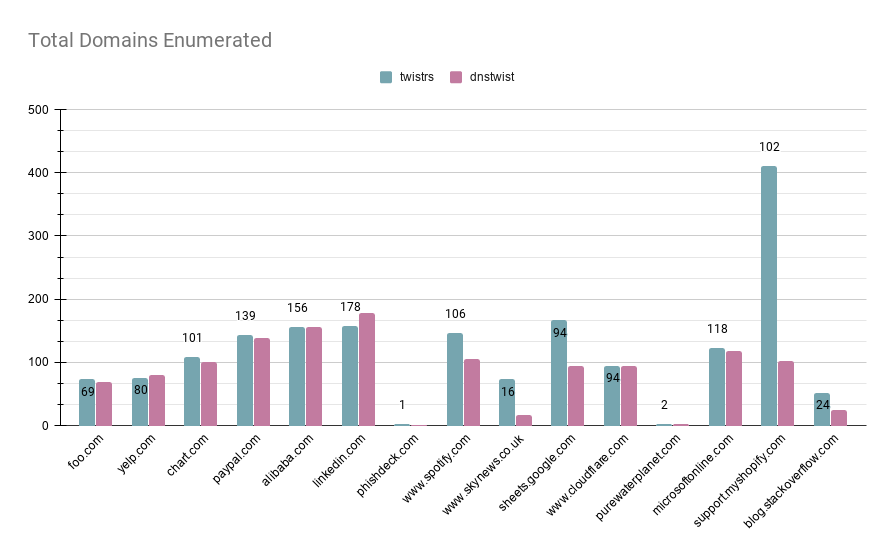
There seems to be an odd edge-case with https://www.linkedin.com that during the time of writing is unknown, but is being tracked.
Execution Time
While the execution time for twistrs is still not fantastic, I am quite pleased at how linear the execution times are compared to dnstwist. This is particularly evident once we start reaching the longer domains.
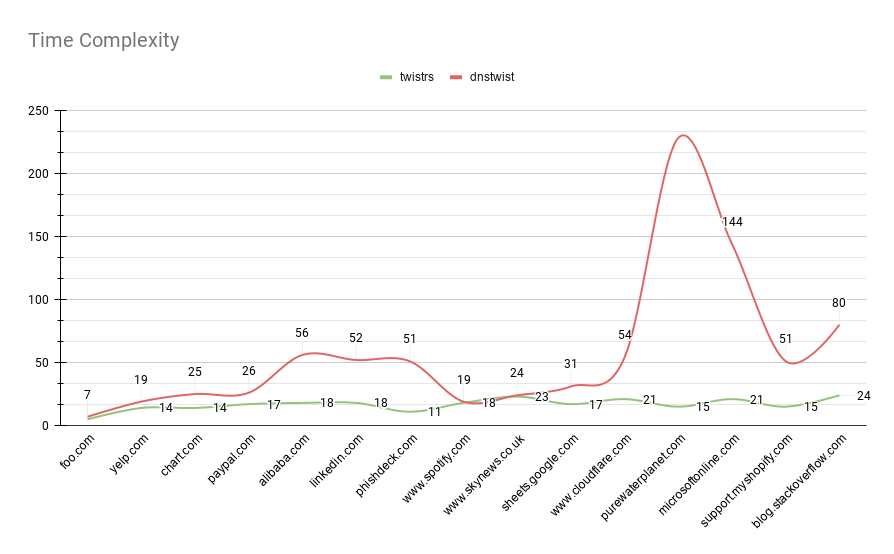
There are no major concerns here. One interesting story is that earlier on, when implementing the Tokio mpsc example, I was still yielding sub-par results. Turns out that the previously DNS resolution itself, was not asynchronous. One StackOverflow question later and we found the case of the issue.
Performance Remarks
In my first attempt to take a closer look at the internals I decided to profile the CLI example and generate a flamegraph. My initial assumption was that most of the execution time would be allocated to host lookups, however that took 10.8% of total execution time. Instead, most of the time was actually absorbed by Tokio for task scheduling and context switching. I am not quite sure what to make of this just yet; I am more than open to suggestions.
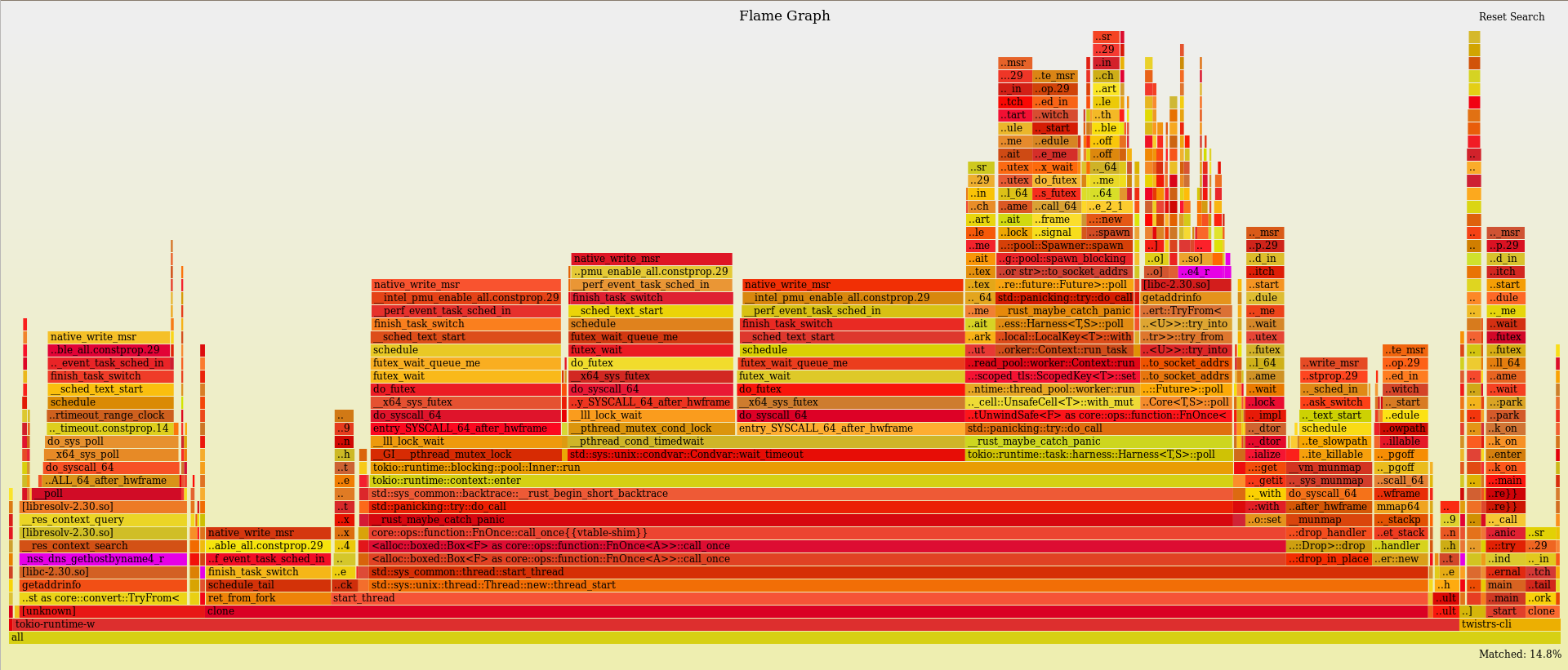
Some other possible ideas revolve around order of performing the host lookups and additonally, being a bit more selective about the permutations that we bother to lookup. As interesting as bitsquatting might be for example, if it generates 5% of permutations, but yields results 0.01% of times, it may not be worth the additional overhead(?).
Conclusion
Miscellaneous
I have started documenting the library so that it’s available on docs.rs. I wanted to mention how fantastic the ecyosystem is for this. The cargo utilities, the automated hosting of docs, the granularity of the documentation itself, is absolutely fantastic, especially coming from the Python world.
Lastly the library is still in early beta stage (0.1.0-beta) but it’s available on crates.io should you wish to play around with it.
Next Steps
There are still a couple of things to really get out of the way quickly, particularly:
- Understanding how to better handle and propagate errors, and remove a lot of the ugly unwrap(). This is currently a mess and something I need to overhaul.
- Implement remaining enrichment methods that dnstwist implements.
- Go through all the @TODO and @CLEANUP (hint: there is a lot).
- Really take a closer look at the underlying performance. There’s definitely room to squeeze out better performance. The project is small and well defined, so it’s a great learning ground for performance enhancements.
Future
The goal in the future is to come up with some interesting client implementations of twistrs. Possible open-sourcing or providing a free tool such as dnstwister to the public to subscribe to interesting events happening on their domains that is possibly more developer-friendly.
With that I mind, I thank anyone for getting to this point. I would love to hear your thoughts and feedback on the project and interesting ways to take the project further.anyone
https://upguard.com/blog/typosquatting 2: https://enterprise.verizon.com/resources/reports/dbir/ (pg 13., fig 13.) 3: http://dinaburg.org/bitsquatting.html